Token Cost Optimization Series, Part 1: Stop Sending JSON to Your LLM
JSON repeats field names with every record, burning tokens at scale. Here's a simple format swap that cuts context token usage by 40–58% for tabular data.
If you're sending structured data to an LLM as context — database query results, RAG payloads, agent tool outputs — you're probably using JSON. And you're probably paying more than you need to.
This is Part 1 of a series on token cost optimization. We're starting with one of the easiest wins: stop formatting your input context as JSON.
Why JSON Is Expensive
JSON repeats field names with every record. For a dataset with 1,000 rows and six fields, that's 6,000 redundant key tokens before you've encoded a single value. Add curly braces, quotes, colons, and commas, and the overhead compounds fast.
On a simple four-record dataset, JSON consumes 172 tokens. The same data in a leaner format: 71 tokens — a 58% reduction.

That's not a rounding error. At scale, it's a meaningful chunk of your monthly API bill.
The TOON Format
TOON (Table-Oriented Object Notation) declares the schema once, then streams data CSV-style:
animals[4]{name,category,habitat,diet}:
African Elephant,mammal,savanna,herbivore
Red-Eyed Tree Frog,amphibian,rainforest,carnivore
Blue Poison Dart Frog,amphibian,rainforest,carnivore
Siberian Tiger,mammal,taiga,carnivore
The field names appear exactly once in the header. Every row after that is pure data. LLMs parse it just fine — they're good at structured text patterns, and this one is unambiguous.
When TOON Works Best
Use it when your data is:
- Tabular RAG payloads — retrieved rows from a vector or relational database
- Database query results — anything coming out of SQL or similar
- Agent tool outputs — tool calls that return arrays of uniform objects
- Long-context agentic workflows — especially when you're passing 50+ retrieved records
Token savings in these scenarios typically range from 40–58%.
When to Avoid It
TOON is for input context, not output. Don't use it when:
- You're requesting structured output or function calling from the LLM — use JSON there, it's what the parsers expect
- Your data is plain text instructions wrapped unnecessarily in JSON (just… don't wrap them)
- You have deeply nested or heterogeneous data — TOON shines on uniform tabular structures, not arbitrary trees
Where TOON Fits in Your Pipeline
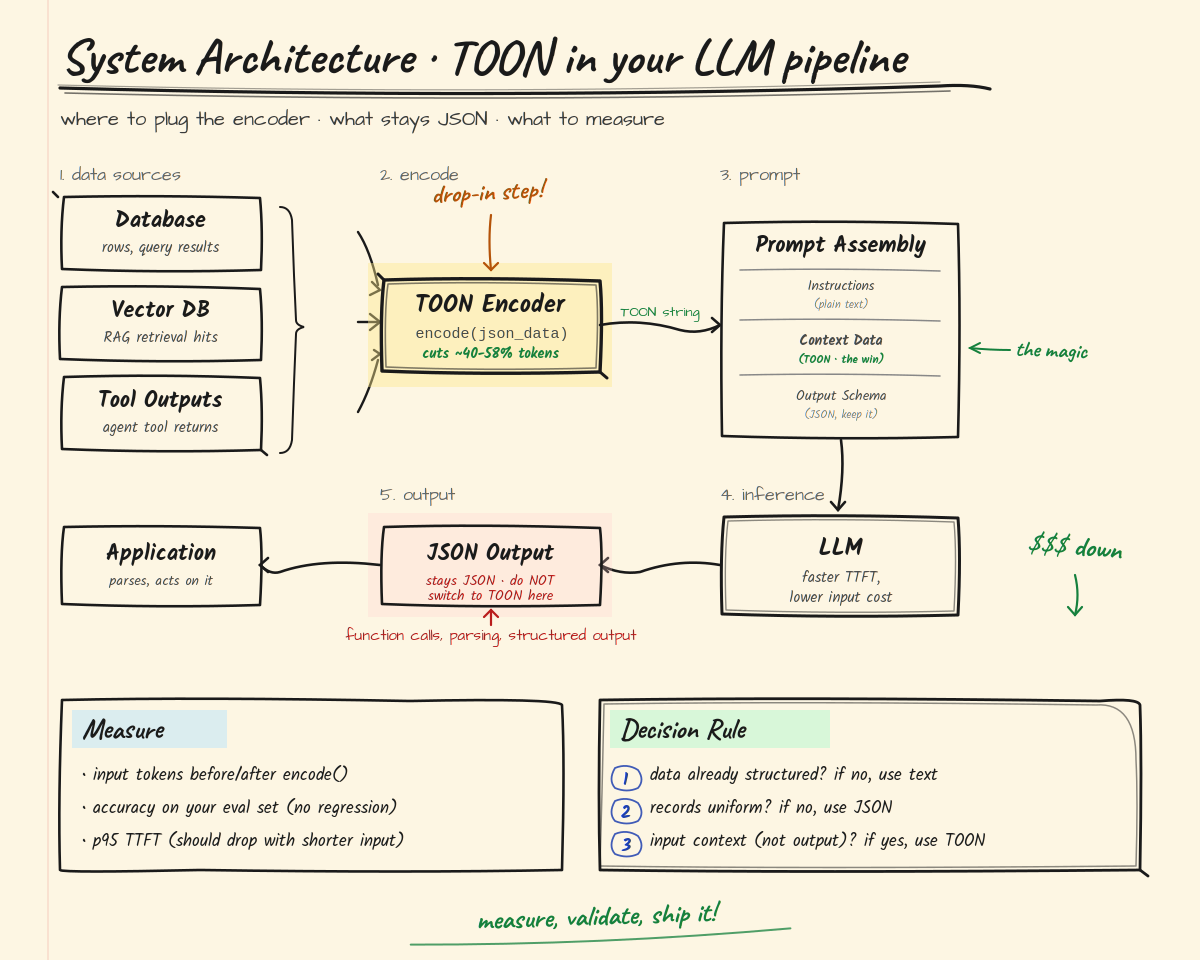
A Simple Decision Framework
Before choosing your format, ask three questions:
- Is the data already structured — database rows, API responses, query results?
- Are the records uniform with consistent fields across rows?
- Is this input context you're sending to the model, not output you're requesting from it?
If you answered yes to all three, swap to TOON and measure your token counts. The savings are real and the change is trivial.
The Broader Point
Most LLM cost optimization advice focuses on the big levers: smaller models, fewer calls, caching. Those matter. But there's a category of low-effort, high-yield changes — formatting being the clearest one — that are easy to overlook because they feel too simple.
This series is about those changes. Next up: chunking strategies that reduce retrieval noise without sacrificing recall.
Written by
Siva Reddy
12+ years in Software Engineering. Now building Agentic AI Solutions at Amazon, where I lead large-scale distributed systems, resiliency, and agentic AI systems.